OpenRouter Fusion: più modelli AI in parallelo, una risposta sola
OpenRouter Fusion manda la stessa domanda a più modelli AI insieme e un giudice li sintetizza: consensus, contraddizioni, costi reali e quando conviene davvero.
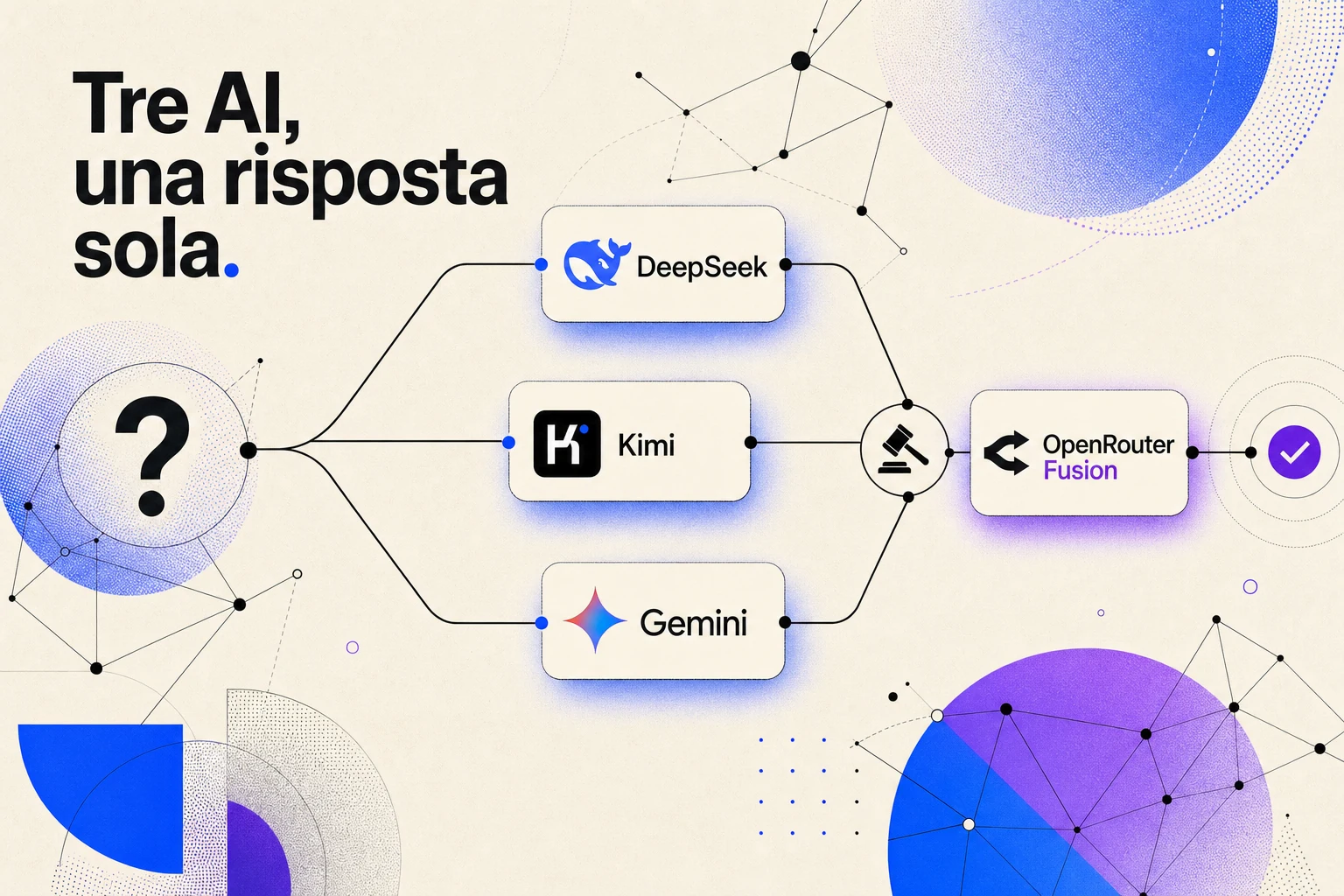
Per due anni la domanda è stata sempre la stessa: quale modello scelgo? GPT, Claude, Gemini, o uno dei modelli cinesi che intanto hanno recuperato terreno. OpenRouter ha appena cambiato la domanda. Con Fusion non scegli più un modello solo. Li interroghi insieme.
Funziona così. Mandi una richiesta, lei parte in parallelo verso tre modelli diversi, ognuno con la ricerca web attiva. Poi un quarto modello, il giudice, legge tutte le risposte e te le mette insieme. Il giudice non fa la media. Confronta, e ti mostra dove i modelli sono d'accordo, dove si contraddicono, e cosa ha notato solo uno di loro.
Per chi prende decisioni con l'AI, questo cambia parecchio. Vediamo come, con i numeri veri usciti in questi giorni.
- Fusion invia la stessa richiesta a 3 modelli in parallelo (preset Budget: Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro), poi un modello giudice sintetizza le risposte.
- Il giudice restituisce una struttura: punti di consenso, contraddizioni, coperture parziali, intuizioni uniche, punti ciechi.
- Nel benchmark DRACO il panel economico batte GPT-5.5 e Opus 4.8 da soli, e resta entro l'1% di Fable 5 costando circa la metà.
- Costa di più e va più lento. Ha senso quando sbagliare costa più di qualche risposta in più.
Cosa fa Fusion, in concreto
OpenRouter è il gateway che dà accesso a oltre 300 modelli con una sola chiave API. Fino a ieri sceglievi il modello e ci parlavi. Da adesso puoi chiamare openrouter/fusion e lasciare che sia lui a interrogare un gruppo di modelli.
Di base il panel è composto da 3 modelli che girano insieme, ma puoi configurarne da 1 a 8. Ci sono due preset pronti: general-high, il gruppo più forte, e general-budget, quello veloce ed economico. Il Budget mette al tavolo Gemini 3 Flash, Kimi K2.6 e DeepSeek V4 Pro. Tre famiglie diverse, tre modi diversi di ragionare.
Ogni modello del panel lavora con web_search e web_fetch attivi. Quindi non rispondono solo con quello che hanno in pancia: cercano anche fonti aggiornate mentre rispondono. Anche il giudice ha questi strumenti.
Il giudice non fonde le risposte, le confronta
Qui sta la parte interessante. Tante soluzioni "multi-modello" prendono le risposte e te ne sputano fuori una sola, frullata. Fusion fa un'altra cosa.
Il giudice legge tutto e restituisce una struttura, in pratica una mappa:
- Consenso: i punti su cui tutti o quasi tutti i modelli concordano. Questi valgono di più, sono ad alta confidenza.
- Contraddizioni: dove i modelli si smentiscono a vicenda. Esattamente i punti dove ti conviene guardare meglio prima di decidere.
- Coperture parziali: risposte incomplete, che dicono mezza verità.
- Intuizioni uniche: la cosa che ha visto un modello solo e gli altri si sono persi.
- Punti ciechi: quello che non ha trattato nessuno.
Leggi questo elenco e ti accorgi che il valore non è "una risposta migliore". È sapere quanto fidarti di ogni pezzo della risposta. Su un consenso a tre puoi muoverti. Su una contraddizione, vai a verificare. È un controllo di qualità che di solito tocca fare a mano, fatto dalla macchina.
I numeri: il panel economico batte i modelli singoli
OpenRouter ha pubblicato i risultati su DRACO, un benchmark che misura l'accuratezza su compiti di ricerca. Qui sotto i punteggi che contano.
Tre modelli di fascia media, messi insieme, superano i modelli di punta usati da soli. Il panel Budget arriva a 64,7%, mentre Opus 4.8 da solo si ferma a 58,8% e GPT-5.5 a 60,0%. Sopra a tutti c'è il preset Quality (Fable 5 più GPT-5.5, con Opus a fare da giudice) che tocca 69,0%, contro il 65,3% di Fable 5 in solitaria.
La cosa che colpisce di più è il prezzo. Il panel economico resta entro un punto da Fable 5 costando circa la metà.
Perché funziona: l'errore di uno raramente è l'errore di tutti
L'idea sotto Fusion non è nuova, ma adesso è alla portata di una chiamata API. Quando un solo modello sbaglia o si inventa qualcosa, te ne accorgi solo se vai a controllare. Quando la stessa domanda passa da tre modelli diversi, l'allucinazione di uno di solito non combacia con quella degli altri. Resta isolata, e si vede.
È lo stesso motivo per cui in azienda le decisioni grosse non le prende una persona sola. Metti tre teste competenti sullo stesso problema e quello su cui concordano è terreno più solido. Quello su cui litigano è il punto che meritava una riunione. Gli studi sugli ensemble di modelli vanno tutti in questa direzione: già con due o tre modelli che votano, l'accuratezza sale e le risposte campate per aria calano.
Il consenso, qui, diventa un segnale di affidabilità. E averlo scritto nero su bianco dal giudice ti risparmia il lavoro di confrontare tre risposte riga per riga.
Il prezzo da pagare
Non è gratis, in nessun senso.
Chiami tre o quattro modelli invece di uno, più il giudice. Il conto si moltiplica: il preset Quality costa circa tre volte una singola chiamata a Opus 4.8. E aspetti di più, perché il sistema va alla velocità del modello più lento del gruppo, quindi due o tre volte i tempi di una richiesta normale.
OpenRouter stessa lo dice chiaro: Fusion è esagerato per le domande tattiche e veloci. Va usato quando il costo di sbagliare supera il costo di qualche risposta in più. Per chiedere un riassunto o sistemare una mail, resta una martellata su una vite.
Cosa farne, se hai un'azienda
Non ti serve per forza OpenRouter per usare il principio. Se devi valutare un fornitore, leggere una clausola contrattuale, fare una prima analisi di un mercato o controllare un dato prima di metterlo in un documento che gira, vale la pena interrogare più modelli e tenere d'occhio le contraddizioni. Fusion automatizza questa abitudine e te la restituisce ordinata, ma l'abitudine puoi prendertela da subito.
Dove invece non ha senso: assistenza clienti in tempo reale, generazione di contenuti a volume, qualsiasi cosa dove la velocità conta più della certezza. Lì un modello singolo, scelto bene, fa il suo.
La direzione però è segnata. Per i compiti seri stiamo passando dal modello singolo al gruppo di modelli che si controllano a vicenda. Chi lavora con l'AI in azienda farebbe bene a ragionare per panel, non per singolo strumento, almeno quando la posta è alta.
Se vuoi capire dove un meccanismo del genere si incastra nel resto, abbiamo raccontato lo stack tecnico di un agente AI in sei livelli e fatto i conti in tasca a Fable 5, il modello che qui fa da giudice. Se invece parti da zero, la nostra roadmap per diventare il riferimento AI in azienda è il punto da cui cominciare.
Tag
Articolo scritto da
Consulente IT & AI per PMI italiane · Prato
Founder di Unicorn Digital. Consulente IT e AI per PMI italiane, basato a Prato. Scrive di intelligenza artificiale applicata alle imprese dal 2015.
Letture correlate

Palantir contro tutti: perché Karp dice che l'industria AI è «completamente pazza»
Il CEO di Palantir Alex Karp accusa OpenAI e Anthropic di far pagare token senza valore reale. Cosa c'è davvero dietro lo scontro e cosa impararne se usi l'AI in azienda.
Loop engineering: come i pro usano Claude Code nel 2026
Boris Cherny, il creatore di Claude Code, non scrive più prompt: scrive loop. Cos'è il loop engineering, i quattro tipi di ciclo e cosa cambia per la tua azienda.
12 LLM Open Source da Conoscere nel 2026
Guida ai 12 migliori LLM open source del 2026: Llama 4, DeepSeek V4, Qwen3, Gemma 4, GLM 5.2 e altri. Punti di forza, licenze e come installarli con Ollama.