Claude Skills che imparano da sole: come si costruiscono con Eval e Memory
Una Claude Skill può accumulare esperienza ad ogni utilizzo grazie a tre componenti: eval loop pass/fail, file di memoria learnings.md e doppio agente che crea e valuta. Guida pratica per chi vuole agenti AI che migliorano nel tempo.
Il problema più sottile dell'AI in azienda è la memoria organizzativa. Non quella tecnica dei token e del contesto, ma il sapere accumulato sul tuo modo di lavorare. Ogni volta che apri una nuova sessione con Claude, ChatGPT o Gemini, il modello ricomincia da capo. La cosa che gli avevi spiegato martedì, mercoledì non se la ricorda. Le correzioni fatte su un workflow scompaiono insieme alla finestra di contesto. Per chi usa l'AI su task ripetuti (riassumere ticket di supporto, classificare CV, generare report) questo significa pagare ogni volta il costo di rieducare il modello da zero.
Negli ultimi mesi è emerso un pattern semplice per risolvere il problema, almeno dentro l'ecosistema delle Claude Skills. L'idea sta in tre file e un doppio agente. Sotto le voci tecniche c'è un'intuizione che vale la pena spiegare bene, perché tocca da vicino chiunque voglia agenti AI seri in produzione.
Il problema: agenti che non imparano
Una Claude Skill, all'origine, è una cartella con dentro un file SKILL.md. Quel file dice all'agente come comportarsi quando viene attivato: a cosa serve la skill, che passi seguire, che cosa evitare. Funziona bene, fino a quando non funziona. Il primo giorno la skill scrive una mail di vendita decente. Il secondo giorno la riapri e produce esattamente lo stesso errore di tono che le avevi corretto il giorno prima.
Il motivo è strutturale: la skill è statica. Non c'è un meccanismo che converta le correzioni dell'utente in modifiche persistenti delle istruzioni. Tutto quello che impari durante la sessione muore con la sessione. Per un uso una tantum va bene così. Per un agente che si occupa di un processo aziendale ricorrente, è un buco grosso.
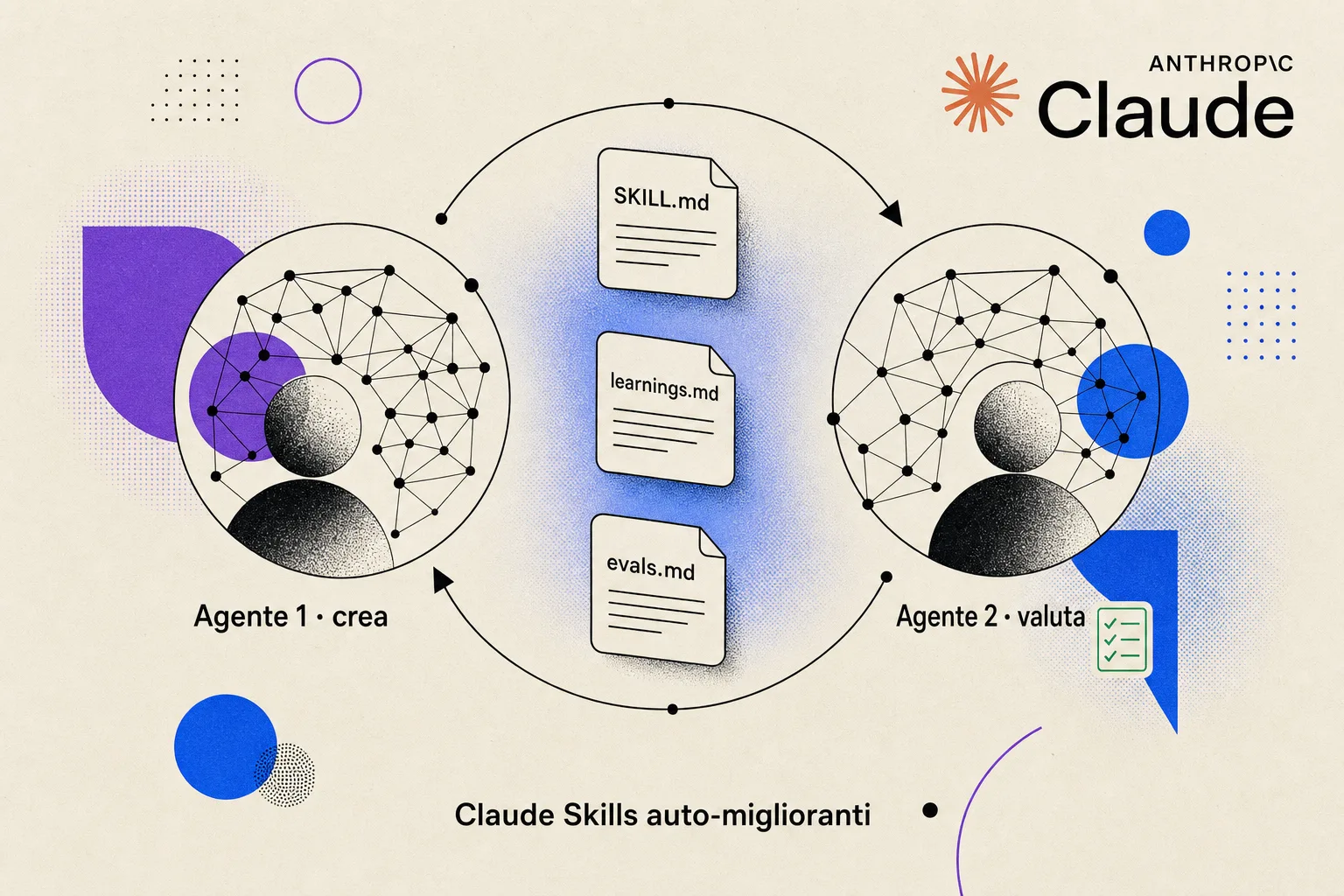
Tre file, una skill che cresce
Il setup minimo per una skill auto-migliorante richiede tre file dentro la stessa cartella.
Il primo è il classico SKILL.md. Contiene le istruzioni operative iniziali, scritte come al solito. È lo scheletro.
Il secondo si chiama learnings.md ed è la memoria persistente della skill. Ad ogni utilizzo importante (un completamento riuscito, un errore corretto, una preferenza emersa) la skill aggiunge un'osservazione a questo file. Niente di sofisticato: una riga al massimo due, in linguaggio naturale. La regola è la stessa che si usa quando si tiene un diario tecnico: ogni voce deve essere abbastanza specifica da essere utile fra tre mesi, abbastanza concisa da essere letta in due secondi. Sul ruolo della memoria persistente negli agenti torneremo, perché è il pezzo che fa la differenza tra un assistente e un collaboratore.
Il terzo file è evals.md: la batteria di test che decide se una versione della skill è buona. Qui sta una delle scelte progettuali più importanti, e la spieghiamo subito.
Pass o fail, niente voti numerici
Quando si valuta un output di un'AI viene istintivo dare un punteggio. Sette su dieci. Quattro stelle su cinque. È quasi sempre un errore. I modelli linguistici, quando vengono usati come giudici, non distinguono in modo affidabile un 3 da un 4 su una scala di cinque. La differenza tra "decente" e "buono" è soggettiva e ondeggia, anche all'interno della stessa giornata.
Quello che invece i modelli fanno bene è una decisione binaria: questo output passa il test, oppure no. Per ogni eval, si scrive una asserzione vera/falsa precisa: "la mail contiene una call to action", "il sommario è inferiore a 100 parole", "il preventivo cita correttamente l'IVA italiana". L'agente valutatore restituisce solo pass o fail. Sopra ad un numero di eval sufficienti (di solito 20-30 per workflow serio) il pass rate diventa la metrica unica della qualità della skill. Si sale da 60% a 80%? La skill è migliorata. Si scende? Si rolla back.
Il doppio agente: chi crea non valuta
Il terzo pezzo del puzzle è il pattern dei due agenti. Un agente esegue il lavoro (genera la mail, classifica il CV, scrive il report). Un secondo agente, lanciato in una sessione separata con context window pulita, fa solo il giudice: legge l'output, legge gli eval, dichiara pass o fail.
Avere due agenti distinti, ognuno con la sua memoria, è importante per una ragione concreta. Un modello che ha appena scritto un testo è influenzato dal proprio output. Tende a difenderlo. Se gli chiedi nella stessa sessione "questo è buono?", la risposta sarà generosa. Un secondo agente, che non sa nulla del processo di scrittura e legge solo il risultato, è un giudice molto più severo. La differenza si vede subito sui pass rate: gli stessi output scendono in media di 15-20 punti percentuali quando il giudice è separato.
learnings.md per la prossima sessione.Cosa succede dopo venti minuti di setup
Una volta che la skill ha i tre file e il valutatore separato, succede una cosa interessante: si possono lanciare cicli di auto-miglioramento senza supervisione. L'agente esegue cento volte la stessa skill su cento input diversi, il valutatore segna pass/fail per ognuno, gli errori più frequenti vengono distillati in nuove righe dentro learnings.md. La sessione successiva la skill parte già più sveglia.
Il pattern ricorda da vicino quello che abbiamo descritto raccontando un founder che gestisce un'azienda intera con un esercito di agenti AI e i dynamic workflows di Claude Opus 4.8. Cambia la scala (qui parliamo di un singolo workflow ben definito, non di un'intera azienda agentificata) ma l'ingrediente attivo è lo stesso: la memoria persistente e gli eval automatici sono quello che separa un giocattolo da uno strumento produttivo.
Quando vale la pena in una PMI
Non tutte le skill meritano questo setup. Per un task una tantum (la presentazione di lunedì, la mail al fornitore) basta un buon prompt scritto bene. La macchina del miglioramento continuo costa tempo a impostarla, e quel tempo si ripaga solo quando la skill verrà richiamata cento volte, mille volte.
Tre scenari tipici dove ne vale la pena, da quello che vediamo nei nostri progetti:
Classificazione massiva. Smistare i ticket di assistenza, etichettare i lead in arrivo dal sito, categorizzare CV. Volumi alti, decisione semi-strutturata, una percentuale di errore che si paga in ore di rilavorazione.
Generazione di asset ripetitivi. Descrizioni prodotto per e-commerce, post LinkedIn per la profilazione editoriale dell'azienda, brief per la fotografia. Output che devono mantenere uno stile coerente nel tempo, dove uno scostamento di tono si vede subito.
Compilazione di documenti regolati. Preventivi, contratti, report periodici. Qui un pass rate misurabile su check binari (ha l'IVA giusta, ha il riferimento contrattuale, ha la data di scadenza) trasforma l'AI da rischio a risorsa. In aree così sensibili, la spinta in più di una consulenza IT specializzata che conosce il processo aziendale prima di automatizzarlo evita di partire dal piede sbagliato.
In tutti questi casi il loop a due agenti diventa il modo più semplice per trasformare l'AI da gadget a fornitore stabile. Per il resto va benissimo continuare a usare Claude (e le sue sorelle) come si è sempre fatto: una sessione, un prompt, un risultato. La macchina che migliora da sola serve quando la stessa cosa va fatta cento volte, e venti minuti di setup oggi diventano centinaia di ore risparmiate fra sei mesi.
Per scegliere quale modello adottare in un workflow aziendale specifico abbiamo dedicato una guida pratica in ChatGPT vs Claude vs Gemini per la tua azienda.
Tag
Articolo scritto da
Consulente IT & AI per PMI italiane · Prato
Founder di Unicorn Digital. Consulente IT e AI per PMI italiane, basato a Prato. Scrive di intelligenza artificiale applicata alle imprese dal 2015.
Letture correlate

Palantir contro tutti: perché Karp dice che l'industria AI è «completamente pazza»
Il CEO di Palantir Alex Karp accusa OpenAI e Anthropic di far pagare token senza valore reale. Cosa c'è davvero dietro lo scontro e cosa impararne se usi l'AI in azienda.
Loop engineering: come i pro usano Claude Code nel 2026
Boris Cherny, il creatore di Claude Code, non scrive più prompt: scrive loop. Cos'è il loop engineering, i quattro tipi di ciclo e cosa cambia per la tua azienda.
12 LLM Open Source da Conoscere nel 2026
Guida ai 12 migliori LLM open source del 2026: Llama 4, DeepSeek V4, Qwen3, Gemma 4, GLM 5.2 e altri. Punti di forza, licenze e come installarli con Ollama.